
Faster R-CNN系列理论整理(附视频讲解)
前言
经过R-CNN和Fast R-CNN的积淀,Ross B. Girshick在2016年提出了Faster R-CNN,在结构上,Faster R-CNN已经将feature extraction,proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
R-CNN(Region with CNN feature)
如图所示:R-CNN分为四步

第一步:

第二步:
第三步:
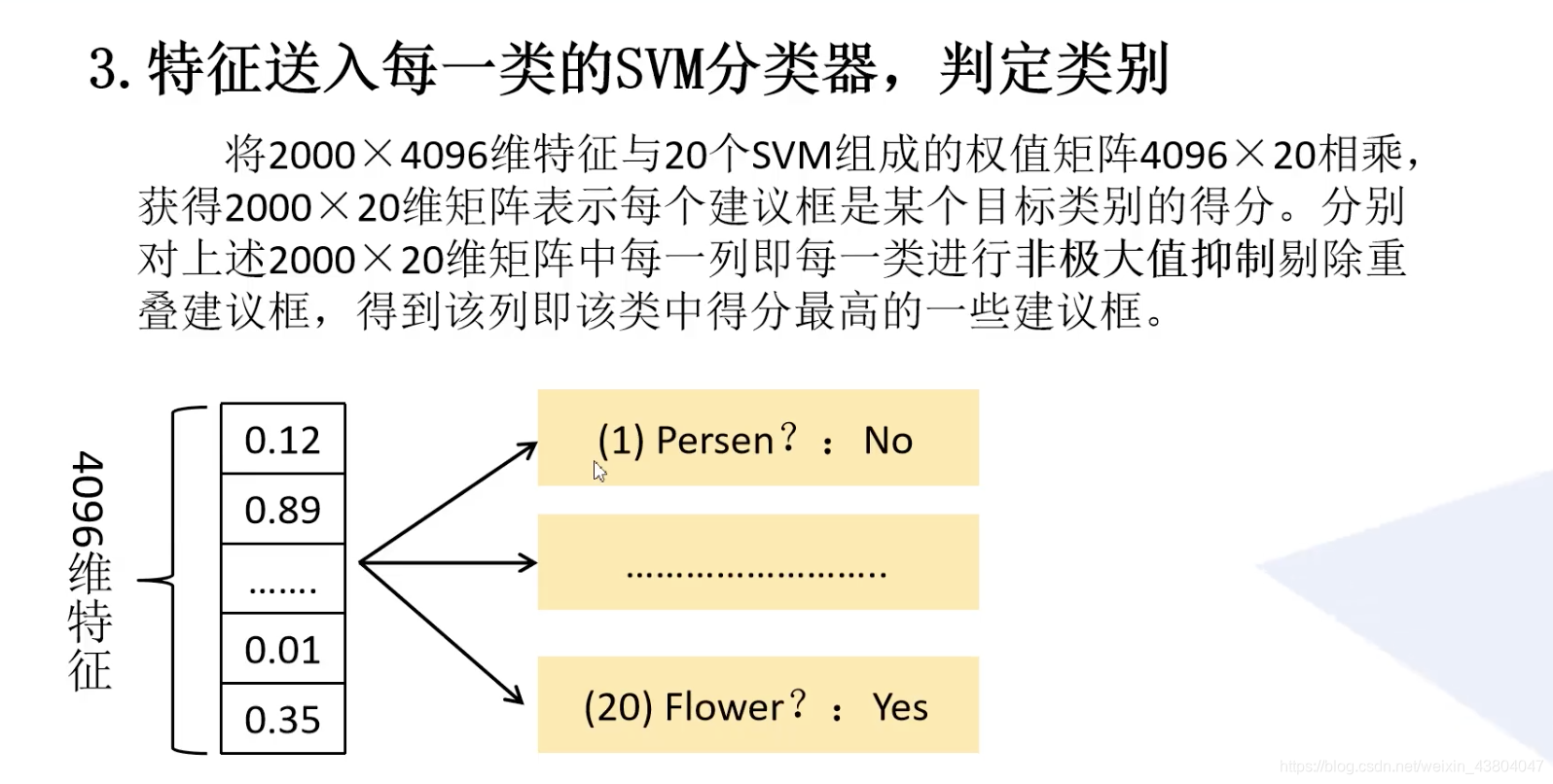
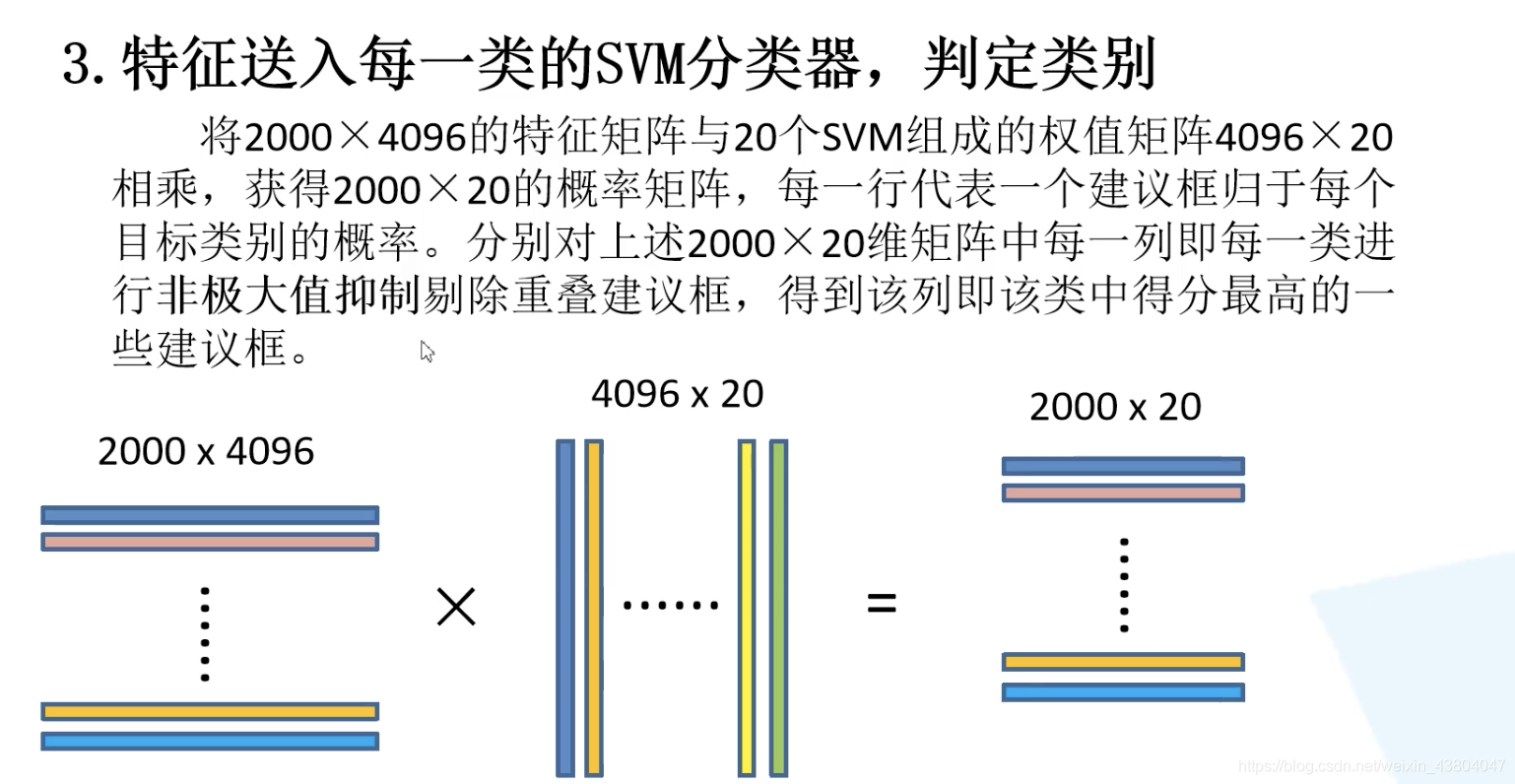

第四步:

R-CNN框架:
- Region proposal(Selective Search)
- Region proposal resize 成227*227送入Feature extraction(CNN)
- Classification(SVM)
- Bounding-box regression(regression)
R-CNN存在的问题:
-
测试速度慢:测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时约2s,一张图像内候选框之间存在大量重叠,提取特征冗余。
-
训练速度慢:需要训练三个网络(CNN分类网络、SVM分类器和regression网络),而且这三个网络是相互独立的。过程及其繁琐。
-
训练所需空间大:对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘,对非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的特征需要存储数百GB的存储空间。
Fast R-CNN
Fast R-CNN框架
-
一张图像生成2k个候选区域Region proposal(Selective Search)
-
将图像输入到网络得到特征图(其中特征图随机采样成数量均衡的正负样本,即前景物体为正(IOU>0.5),背景为负样本(IOU<0.5)),将SS算法生成的候选框投影到特征图上获得相应的特征矩阵(这样就减少了特征的提取工作,2k个region proposal只需要映射框即可,中间的特征不需要重复提取)。
-
将每个特征矩阵通过ROI pooling层统一缩放到7*7大小的特征图(即不限制图像输入大小),接着将特征图展平通过2个FC层并联得到预测结果。(只用一个网络取代了R-CNN的SVM分类器和regresion回归器)
如图所示为Fast R-CNN示意图:
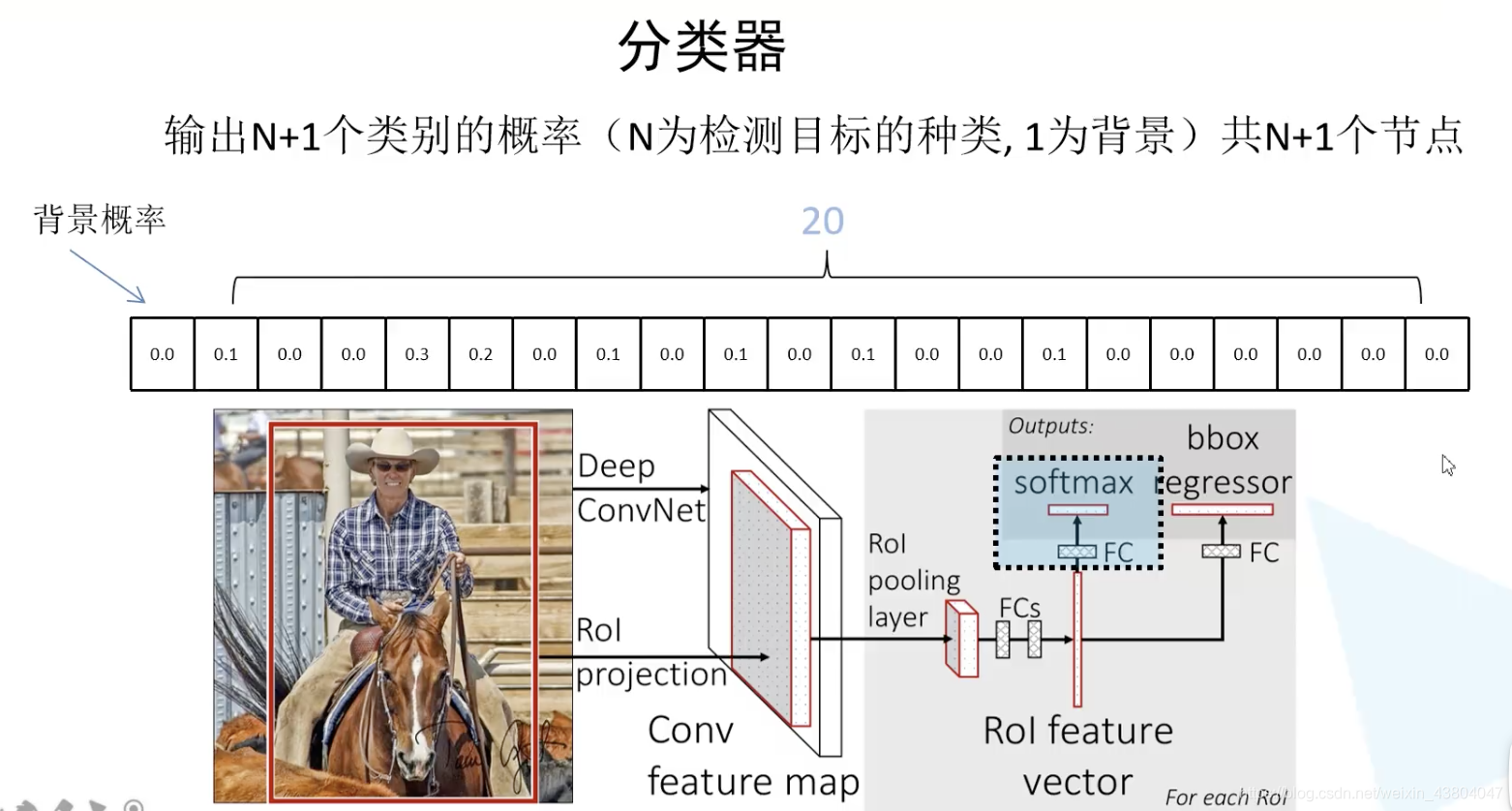
Faster R-CNN
Faster R-CNN的框架
- 将图像输入到网络得到相应的特征图
- 使用RPN结构生成候选框,将候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层统一缩放到7*7大小的特征图,接着将特征图展平通过2个FC层得到预测结果。
如图所示为Faster R-CNN示意图:

与Fast R-CNN不同的是SS算法替换成了RPN,搞懂了RPN,Faster R-CNN也就懂了

如图所示为计算k个anchor boxes:采用滑动窗口
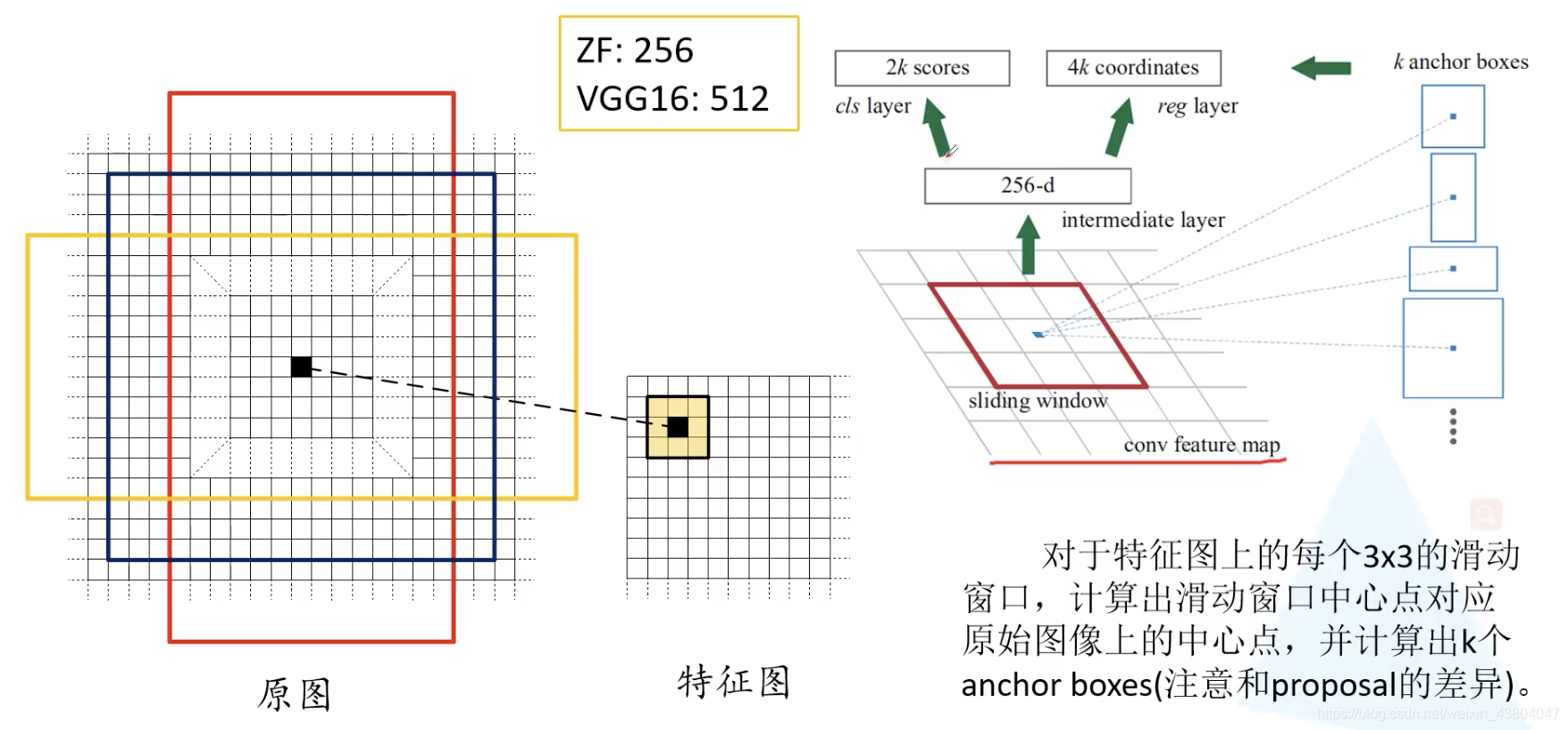
计算不同尺度的anchor:
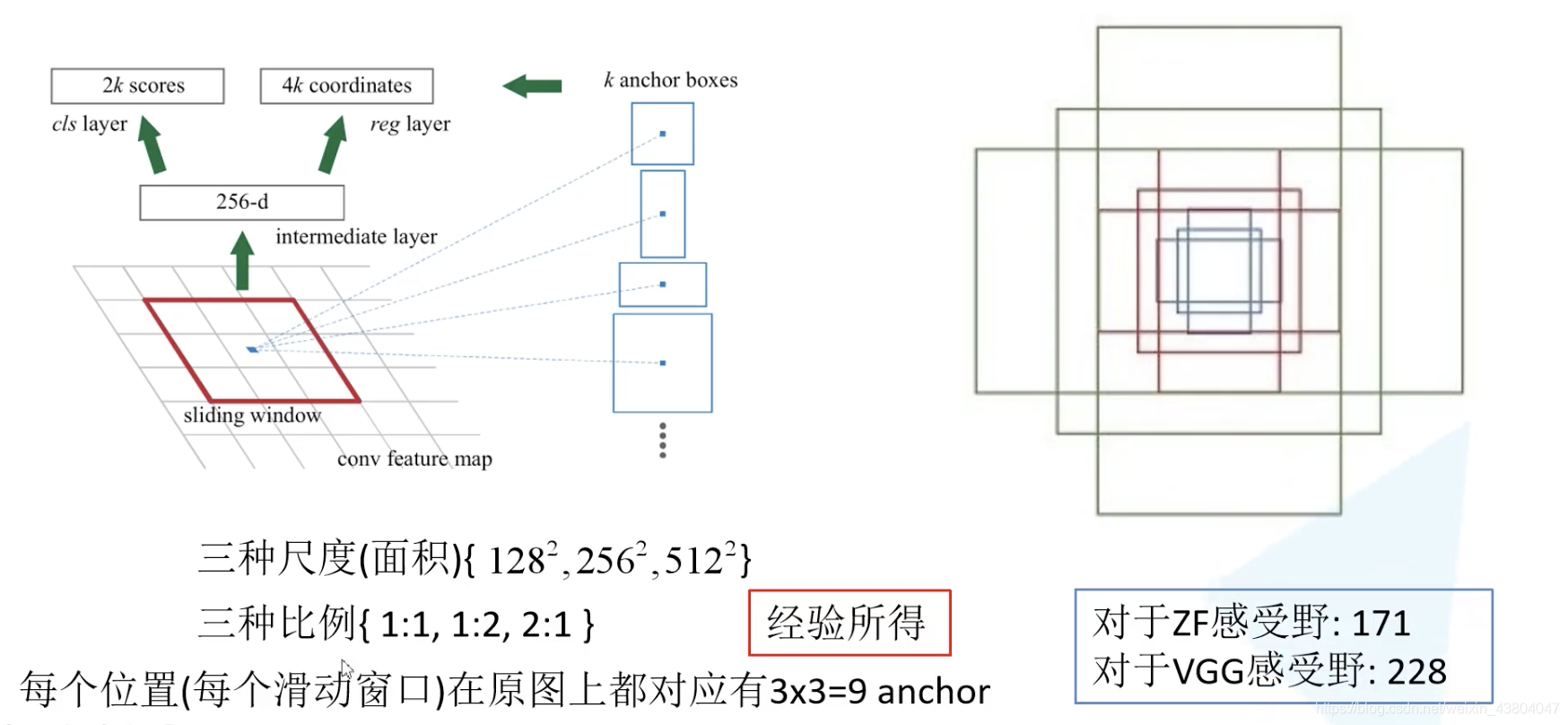
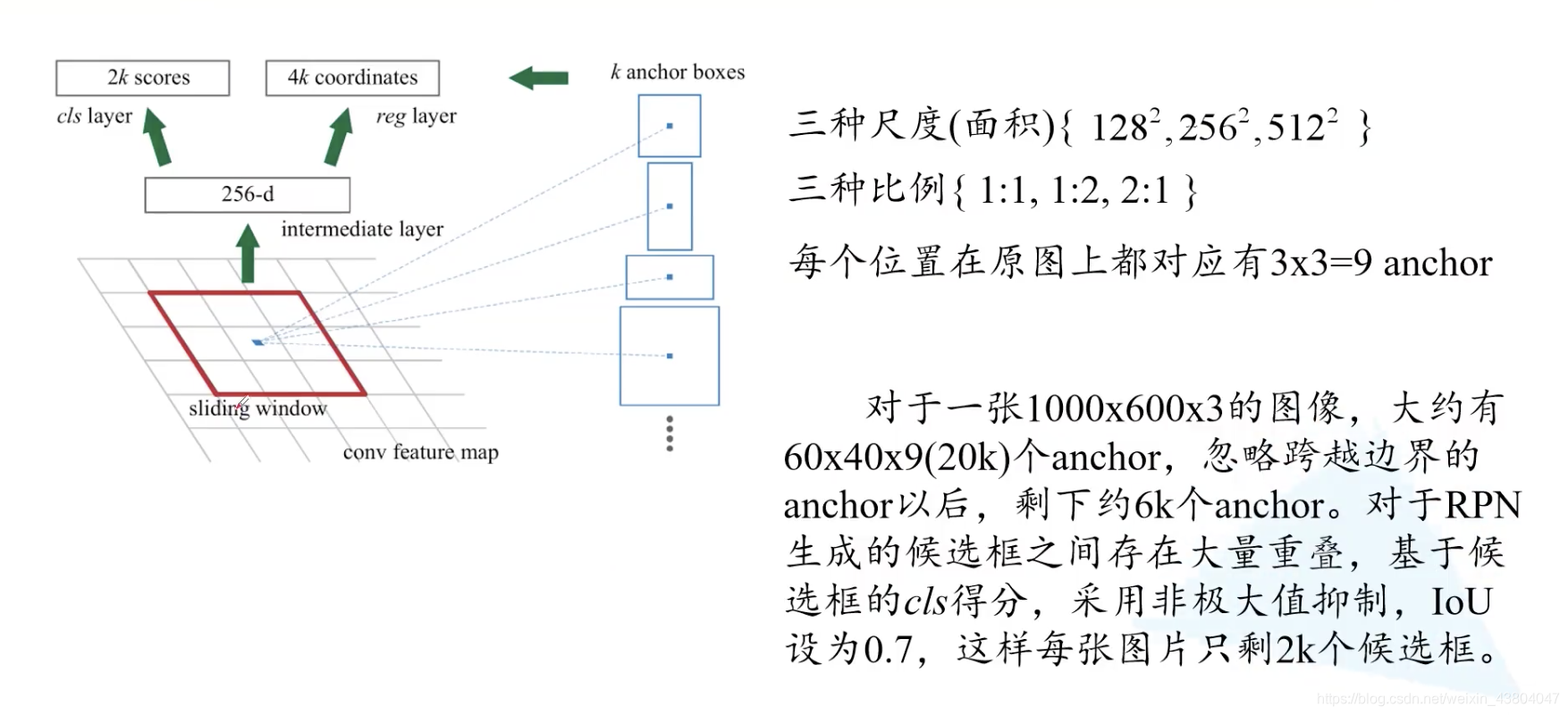
以上即为RPN(region proposal network)
到此结束
如想深入了解可看相关视频Faster RCNN理论合集

