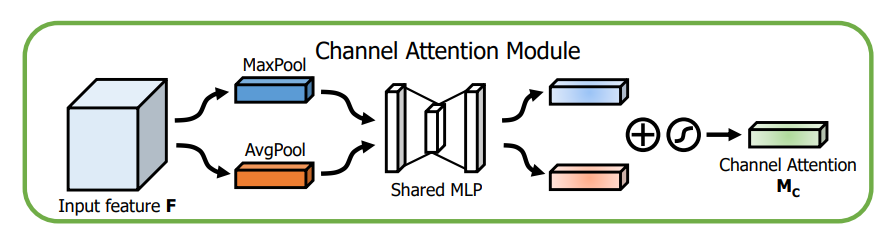
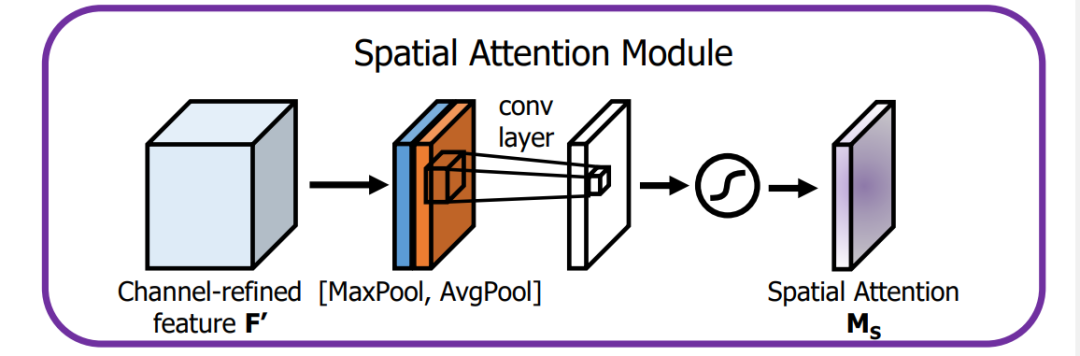
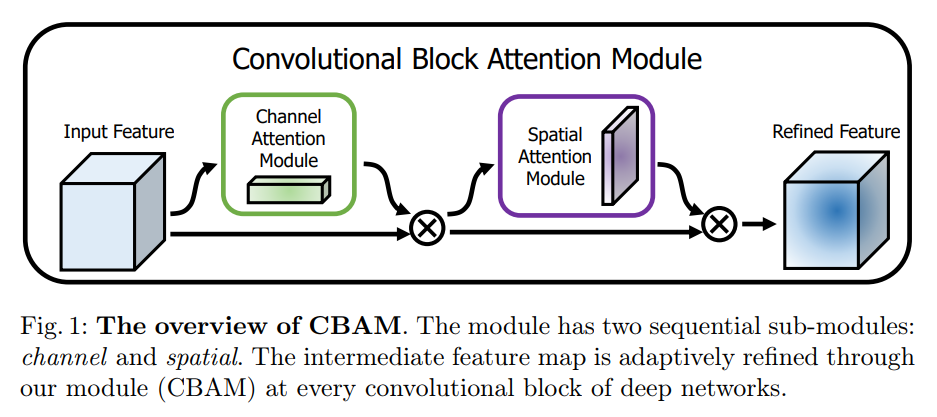
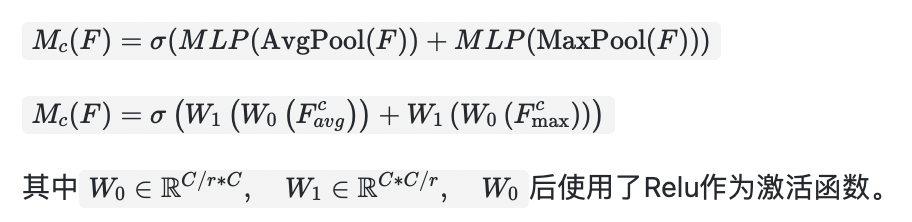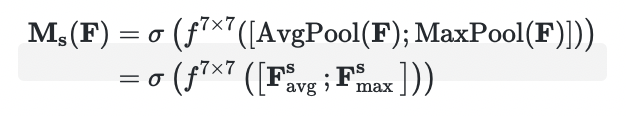1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
| import tensorflow as tf
import numpy as np
slim = tf.contrib.slim
def combined_static_and_dynamic_shape(tensor):
"""Returns a list containing static and dynamic values for the dimensions.
Returns a list of static and dynamic values for shape dimensions. This is
useful to preserve static shapes when available in reshape operation.
Args:
tensor: A tensor of any type.
Returns:
A list of size tensor.shape.ndims containing integers or a scalar tensor.
"""
static_tensor_shape = tensor.shape.as_list()
dynamic_tensor_shape = tf.shape(tensor)
combined_shape = []
for index, dim in enumerate(static_tensor_shape):
if dim is not None:
combined_shape.append(dim)
else:
combined_shape.append(dynamic_tensor_shape[index])
return combined_shape
def convolutional_block_attention_module(feature_map, index, inner_units_ratio=0.5):
"""
:param feature_map : input feature map
:param index : the index of convolution block attention module
:param inner_units_ratio: output units number of fully connected layer: inner_units_ratio*feature_map_channel
:return:feature map with channel and spatial attention
"""
with tf.variable_scope("cbam_%s" % (index)):
feature_map_shape = combined_static_and_dynamic_shape(feature_map)
channel_avg_weights = tf.nn.avg_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_max_weights = tf.nn.max_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_avg_reshape = tf.reshape(channel_avg_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_max_reshape = tf.reshape(channel_max_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_w_reshape = tf.concat([channel_avg_reshape, channel_max_reshape], axis=1)
fc_1 = tf.layers.dense(
inputs=channel_w_reshape,
units=feature_map_shape[3] * inner_units_ratio,
name="fc_1",
activation=tf.nn.relu
)
fc_2 = tf.layers.dense(
inputs=fc_1,
units=feature_map_shape[3],
name="fc_2",
activation=None
)
channel_attention = tf.reduce_sum(fc_2, axis=1, name="channel_attention_sum")
channel_attention = tf.nn.sigmoid(channel_attention, name="channel_attention_sum_sigmoid")
channel_attention = tf.reshape(channel_attention, shape=[feature_map_shape[0], 1, 1, feature_map_shape[3]])
feature_map_with_channel_attention = tf.multiply(feature_map, channel_attention)
channel_wise_avg_pooling = tf.reduce_mean(feature_map_with_channel_attention, axis=3)
channel_wise_max_pooling = tf.reduce_max(feature_map_with_channel_attention, axis=3)
channel_wise_avg_pooling = tf.reshape(channel_wise_avg_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_max_pooling = tf.reshape(channel_wise_max_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_pooling = tf.concat([channel_wise_avg_pooling, channel_wise_max_pooling], axis=3)
spatial_attention = slim.conv2d(
channel_wise_pooling,
1,
[7, 7],
padding='SAME',
activation_fn=tf.nn.sigmoid,
scope="spatial_attention_conv"
)
feature_map_with_attention = tf.multiply(feature_map_with_channel_attention, spatial_attention)
return feature_map_with_attention
feature_map = tf.constant(np.random.rand(2,8,8,32), dtype=tf.float16)
feature_map_with_attention = convolutional_block_attention_module(feature_map, 1)
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
result = sess.run(feature_map_with_attention)
print(result.shape)
|